Semantic Segmentation
Introduction
In this project a Fully Convolution Network is built based on the VGG 16 architecture used for image classification and it is trained on Kitti Road dataset. This is used to perform sematic segmentation to identify road surface from the test set.
Architecture
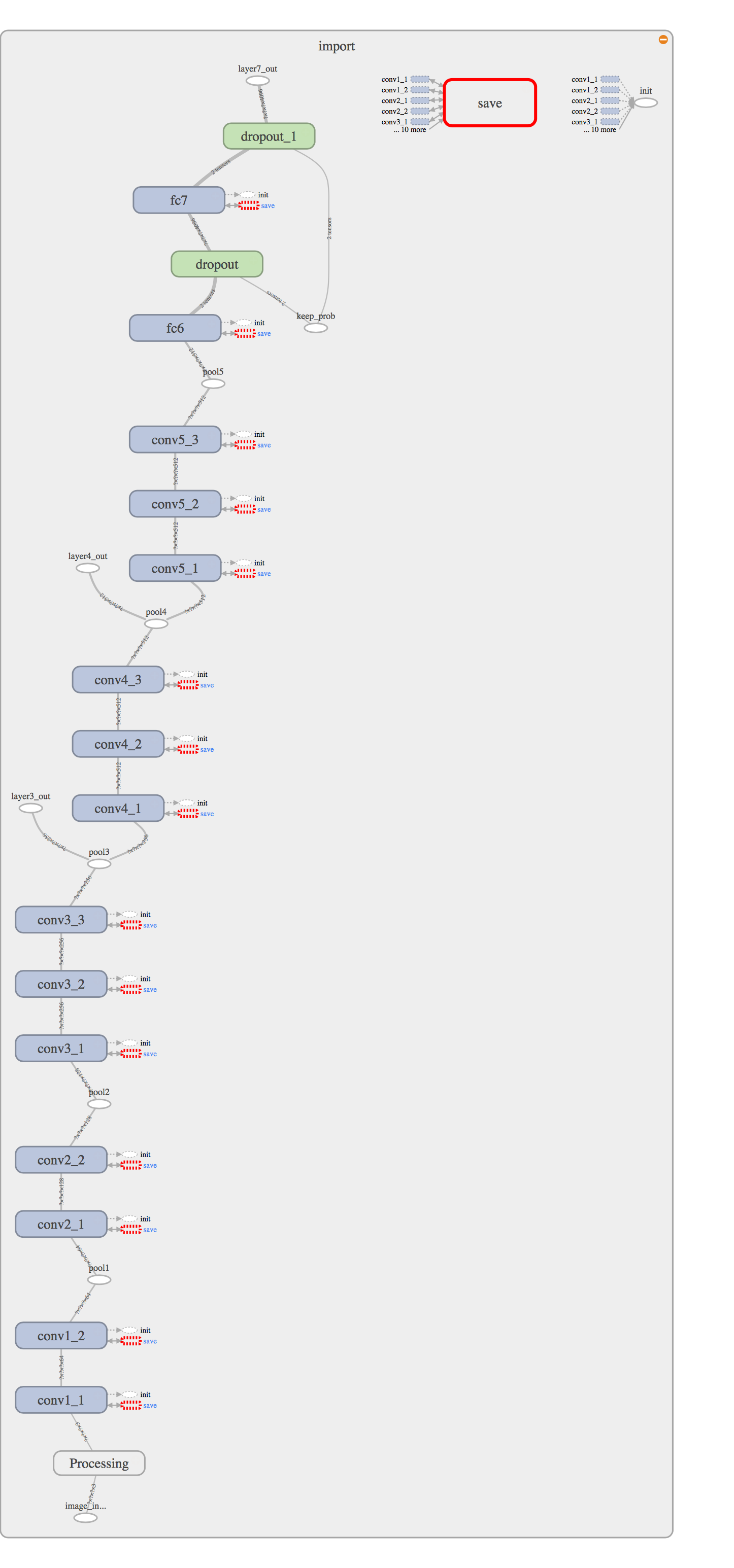
The VGG 16 architecture is originally used for image classification. This architecure consists of 5 convolution layer and 2 fully connected layer.
{kind=link}
- The final fully connected layer is converted to 1x1 convolution by setting the depth equal to number of classes, which is road or not a road in this use case. This layer is upsampled to represent the original image size.
- In order to maintain / preserve the feature information skip connections are used. The skip connection 1 carries information from the 4th convolution layer of the VGG 16 architecture. This is converted to a 1x1 convolution layer and element wise addtion is performed with upsampled 1x1 convolution layer to form skip connection.
- The resultant is upsampled and skip connection is repeated with 3rd convolution layer to preserve more feature information.
- The result is upsampled to generate the final layer.
- All convolution layers, upsampled layers uses a l2-regularisation and kernel initialiser.
Optimiser
The loss function is calculated using cross-entropy and Adam Optimiser is used to reduce the cost.
Training and Hyperparameters
The following hyperparameters are used for training.
- EPOCH - 60
- BATCH SIZE - 5
- Learning Rate - 0.0009
- keep probability - 0.5
Results
The network performed overall well in training and test. The average loss per batch for 50 epoch was reduced up to 0.02.
The following are some of the samples of the result, but there are scenrios where the results could be improved.






Setup
Frameworks and Packages
Make sure you have the following is installed:
- Python 3
- TensorFlow
- NumPy
- SciPy
Dataset
Download the Kitti Road dataset from here. Extract the dataset in the
datafolder. This will create the folderdata_roadwith all the training a test images.
Start
Run
Run the following command to run the project:
python main.py
Note If running this in Jupyter Notebook system messages, such as those regarding test status, may appear in the terminal rather than the notebook.
### Tips
- The link for the frozen
VGG16model is hardcoded intohelper.py. The model can be found here - The model is not vanilla
VGG16, but a fully convolutional version, which already contains the 1x1 convolutions to replace the fully connected layers. Please see this forum post for more information. A summary of additional points, follow. - The original FCN-8s was trained in stages. The authors later uploaded a version that was trained all at once to their GitHub repo. The version in the GitHub repo has one important difference: The outputs of pooling layers 3 and 4 are scaled before they are fed into the 1x1 convolutions. As a result, some students have found that the model learns much better with the scaling layers included. The model may not converge substantially faster, but may reach a higher IoU and accuracy.
- When adding l2-regularization, setting a regularizer in the arguments of the
tf.layersis not enough. Regularization loss terms must be manually added to your loss function. otherwise regularization is not implemented.